How to use it
The app was designed taking special account of the needs of historians but - like any software - requires some skill and background knowledge before it can lead to reasonable conclusions.
We therefore compiled a range of didactic materials which seek to clarify the idiosyncrasies of digitised historical newspapers, of their semantic enrichment produced via natural language processing, and of the exploratory components of our interface.
About digitised newspapers in general
RANKE2 - From the shelf to the web, exploring historical newspapers in the digital age
A lesson prepared for academic teachers (and those willing to self-teach) on on how digitised newspapers change the way historians use newspapers as historical sources, and on how to perform source criticism in the digital age. More here
 → RANKE2 - From the shelf to the web
→ RANKE2 - From the shelf to the web
PARTHENOS MODULE - Collections of digitised newspapers as historical sources
A training module for scholars which provides background knowledge on newspaper digitisation technologies, with a special focus on their impact on both digital sources and the practice of historical research.
 → PARTHENOS MODULE
→ PARTHENOS MODULE
About the impresso app
impresso challenges - how to become an impresso power user
Based on concrete examples, the impresso challenges offer a step-by-step and hands-on guidance through the application. The first challenge introduces the interface features, to make the most of the search tools offered by the application: how to read the frequency lines, how to use topics and named entities as filters, and how to explore the impresso corpus. The second challenge introduces some digital source criticism elements to help you understand the limits inherent to such a digital corpus and its automatically extracted information. Finally, the third challenge proposes to explore the impresso corpus with a more abstract perspective, to illustrate the operationalisation of research questions via the interface features.
 → impresso Challenges
→ impresso Challenges
impresso interface walkthroughs
impresso project overview and app presentation made at the Digital Humanities 2020 conference.
Impresso app presentation made at the 2020 ForumZ event “Reading yesterday’s news in the digital age”
Frequently Asked Questions
FAQs are accessible via the info buttons distributed across the interface, and on the FAQ page. They provide short explanations about text processing, of the interface features and the underlying processes, as well as the terms of use explanations on the copyright status of the impresso materials (images, OCR text, semantic annotations).
 → impresso App FAQ Page
→ impresso App FAQ Page
Diving deeper into Natural Language Processing
The title of this post paraphrases our colleague Max Kemman and relates to the ‘negotiation of practices’ that (should) inevitably happen within interdisciplinary frameworks. Within impresso, we tackle this challenge by, among others, by adopting co-design as one of our core working principles.
Beyond the realisation of an exploration interface capable of answering the needs of its users, our intention is to foster the dialogue between our academic fields (computational linguistics and history), as well as to reflect on changes affecting research environment in the humanities (more on co-design in a soon-to-come glossary entry).

Concretely speaking, impresso co-design is put into practice with an early-stage and continuous participation of historians. This cooperation is materialized via, on the one hand, the definition of research scenarios by historians and, on the other, the explanation and implementation of NLP processes by computational linguists, all these being discussed during workshops.
With this blog post series and tutorials, computational linguists would like to step in the trading zone, and to translate what ‘named entity processing’, ‘topic modeling’, ‘text reuse’ and more mean in practical terms when it comes to searching and exploring a historical newspaper collection. The intention is to sketch possibilities so as to help historians potentially interested in our future interface to plan their research and start operationalizing their questions. We would like to emphasize that the following descriptions are rather concise and will be further explained and illustrated as our work proceeds.
Named entity processing
To put it very briefly, named entity processing corresponds to the tasks of:
- recognizing mentions of entities of interest in texts and classifying them according to a set of predefined categories, usually Person, Organisation and Location, with more less specification (collective vs. individual person, geographical vs. administrative location)
- linking these mentions to unique identifiers in order to deal with homographic names (“John Smith”) referring to different entities and name variants referring to the same entity. This process is also called named entity disambiguation
- identifying relations between entities such as born_in between a person and a location entity, colleague_of between two persons, alma_mater between a person and an organisation (in this case could be of subtype ‘Educational’), etc.
This blog post explains, how we have made use of named entities in the impresso project:
 → Named entity processing in a nutshell
→ Named entity processing in a nutshell
Members of the impresso team organised a workshop at the DH2020 conference on the recognition of historical named entities. You can find all materials here:
 → Named Entity Processing for Digital Humanities
→ Named Entity Processing for Digital Humanities
Topic modeling
To document how we have integrated topic modeling within the impresso project and how they can become part of an explorative workflow we have prepared the following blog posts:
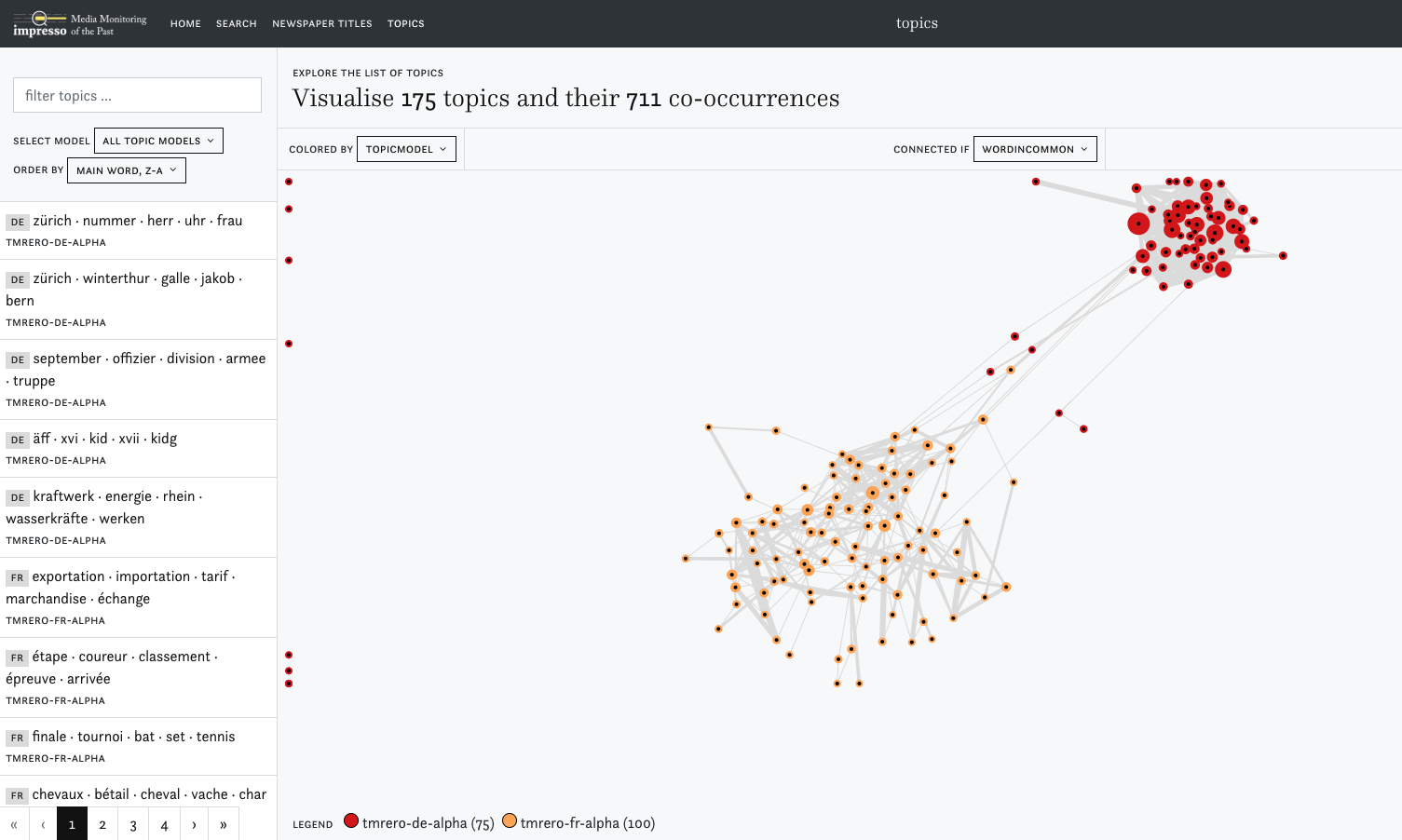 → Explore the list of topics on the impresso interface
→ Explore the list of topics on the impresso interface
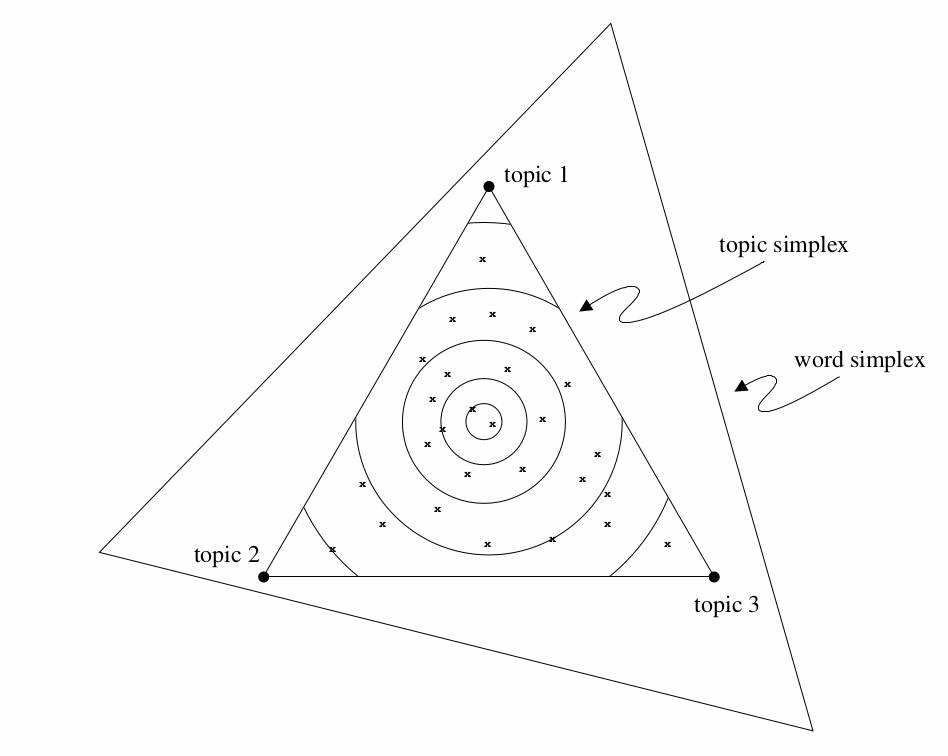 → About Topic Modeling on historical newspapers
→ About Topic Modeling on historical newspapers
Text Reuse
Text reuse allows the detection of similar text passages across a corpus. To learn more about this method we have co-authored a forthcoming lesson on the detection of text reuse using passim for the Programming historian platform
 → Detection of text reuse using passim
→ Detection of text reuse using passim
