Reading yesterday's news in the digital age
Text mining 200 years of historical newspapers.
What can we do with yesterday’s news? Historical newspapers are mirrors of past societies. Published over centuries on a regular basis, they record wars and minor events, report on international, national and local matters, and document day-to-day life. They reflect the political, social and economic contexts in which they were produced and help us understand how people in the past experienced their time. In recent years, newspapers were mass-digitised and are now readily available for consultation online. Keyword search remains the most popular way to find interesting articles - but is there a better way?

The Swiss-Luxembourgish project impresso. Media Monitoring of the Past thinks there is and uses text mining tools to extract, process, link and visualise information from Luxembourgish and Swiss newspapers. This allows us for example to track the mentions of specific persons and places over time, to explore thematics such as sports or culture and to detect reused text passages across newspapers. To access and explore all this newly generated data we developed a new user interface and a range of didactic materials which help to foster a better understanding of the advantages and challenges of digitisation.
Learn more about the project with this clip:
RESOURCES
To help you make the most of the available collections of digitised newspapers, you are invited to check out some pedagogical material the impresso project has produced.
IMPRESSO Challenges
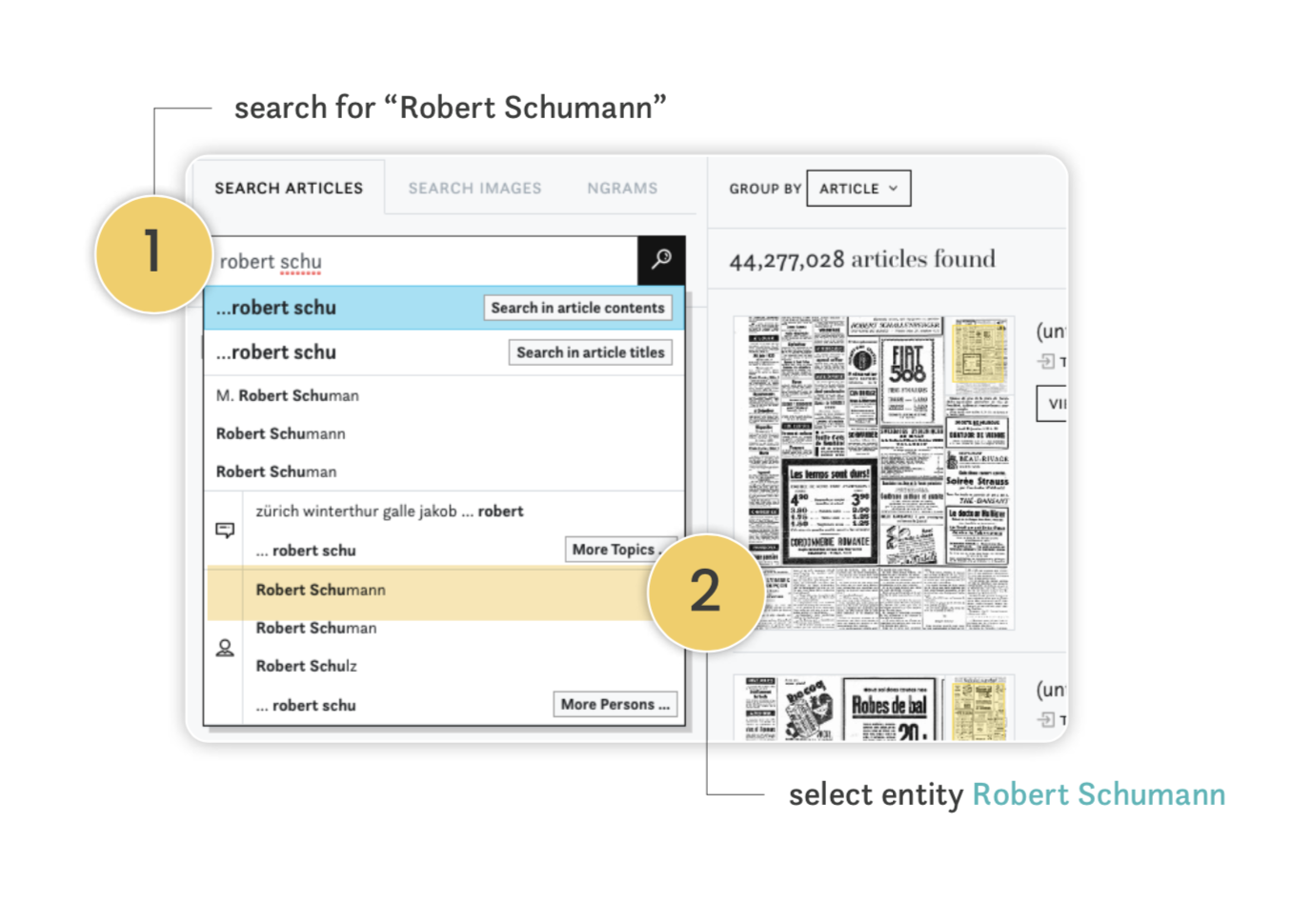
How to explore the newspapers with persons or locations? What are topics good for? What elements can be compared?
Get a better understanding of this interfaces’ features and how they can interact with 3 challenges, starting with an initiation and leading to an expert level use of the interface.
RANKE2 - From the shelf to the web, exploring historical newspapers in the digital age.

A lesson about how digitised newspapers that are available online are changing the way historians use newspapers as historical sources, and ask new skills for applying source criticism. More here
PARTHENOS MODULE - Collections of digitised newspapers as historical sources

A training module destined to offer an academic perspective on digitised newspapers: what changes have been brought about by digitisation, how do they affect the practice of research, and what are the potentialities and current practices when it comes to using historical newspapers for research? More here
Events
In the final year of the project, the impresso team has planned out several events, related to historical and NLP aspects of the digitised newspapers.
Digitised newspapers - a new Eldorado for historians ?

From manual, on-site exploration of microfilm or paper collections to online keyword search over millions of OCRized page, access to digitized newspapers has changed significantly. Coupled with automatic enrichement of sources via text and image processing, this represents a whole world of new possibilities. An Eldorado? Despite undeniable merits, the digital transformation and the new affordance of historical newspapers also brings some drawbacks and possible pitfalls which need to be carefully assessed. The Eldorado workshop, supported by the impresso project, will bring together a group of historians, librarians, computer scientists and designers to discuss how digitisation is changing historical research practices.
More information here
HIPE (Identifying Historical People, Places and other Entities)

HIPE (Identifying Historical People, Places and other Entities) is a named entity processing evaluation campaign on historical newspapers in French, German and English, organized in the context of the impresso project and run as a CLEF 2020 Evaluation Lab. Since its introduction some twenty years ago, named entity (NE) processing has become an essential component of virtually any text mining application and has undergone major changes. Recently, two main trends characterise its developments: the adoption of deep learning architectures, and the consideration of textual material originating from historical and cultural heritage collections. While the former opens up new opportunities, the latter introduces new challenges with heterogeneous, historical and noisy inputs. If NE processing tools are increasingly being used in the context of historical documents, performances are below the ones on contemporary data and are hardly comparable. In this context, the objective of HIPE is threefold:
- to strengthen the robustness of existing approaches on non-standard input;
- to enable performance comparison of NE processing on historical texts; and, in the long run,
- to foster efficient semantic indexing of historical documents in order to support scholarship on digital cultural heritage collections.
More informationhere
see also
Overall Objectives — Computational Linguistics — Design — Historical Research
