Leveraging an unprecedented corpus of newspaper and radio archives, Impresso - Media Monitoring of the Past is an interdisciplinary research project that uses machine learning to pursue a paradigm shift in the processing, semantic enrichment, representation, exploration and study of historical media across modalities, time, languages, and national borders.
Impresso seeks to transcend language and media barriers to enable, for the first time, the joint exploration of a vast corpus comprising both newspaper and radio archives. This initiative spans different modalities, time periods, languages, and national boundaries. Our objective extends beyond simply aggregating collections and enabling full-text search capabilities. We aim to enhance and interconnect these sources by implementing multiple layers of advanced semantic enrichments, all represented within a unified, multilingual vector space. Additionally, our goal is to develop robust, meaningful, and transparent exploration tools specifically tailored for historical research.
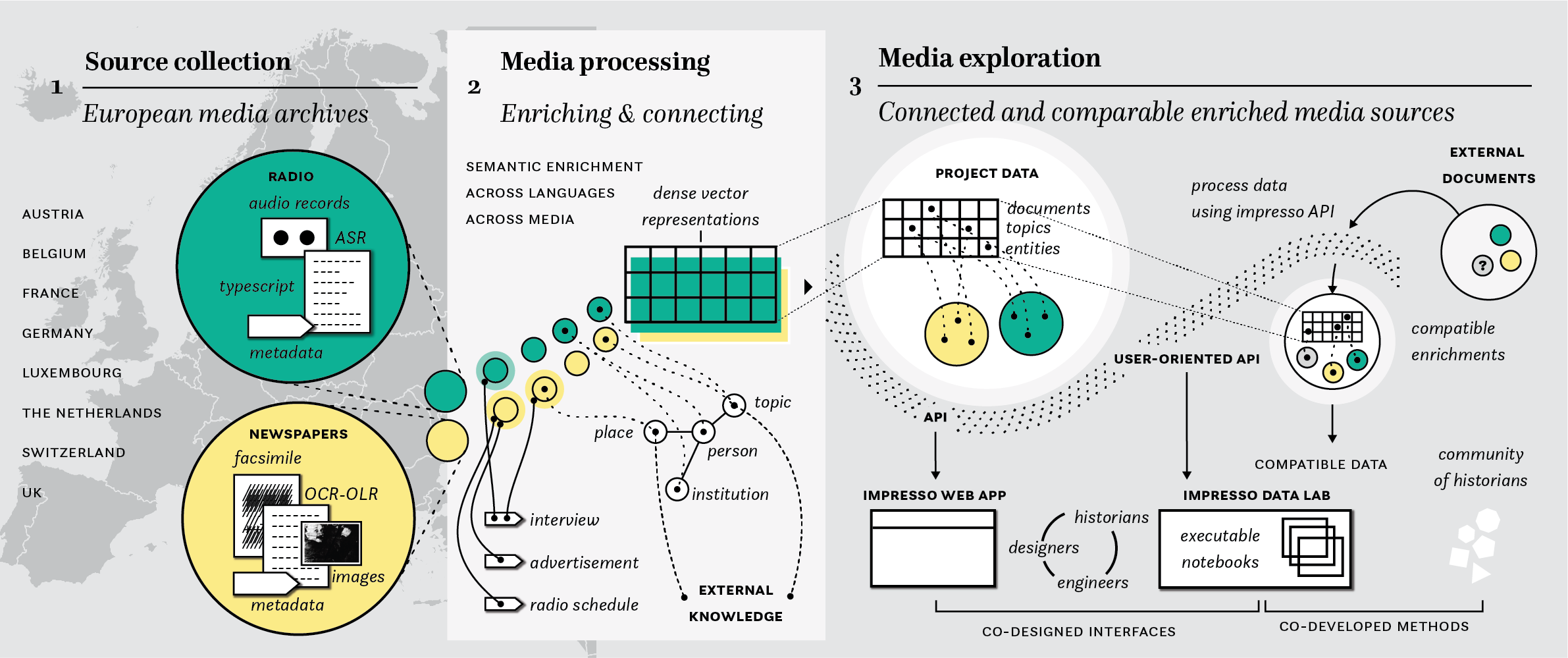
Our work represents not merely an expansion in volume, but a fundamental shift in the approach to processing, representing, and studying sources from a transmedia and transnational perspective. This project is collaboratively designing and developing an open, versatile technological framework to enable seamless exploration of semantically interconnected media archives. Our focus areas include:
- Advancing multilingual natural language processing techniques to convert diverse, unstructured, and noisy historical media sources into semantically enriched data, ultimately interconnected within a shared vector space.
- Progressing the field of digital (media) history, both in terms of research and methodologies.
- Creating and implementing innovative interfaces for exploring, visualizing, and comparing extensive amounts of enriched historical print and audio collections.
Project schema
Historical media reflect the times during which they were created and offer rich insights into past norms, values, knowledge horizons and the historicity of media themselves. Since the 1990s, newspaper and radio archives have undergone massive digitization, and traditional barriers hindering the study of historical media, namely difficult access and tedious exploration, have started to fall.
Millions of facsimiles and digital broadcast records, along with their machine-readable content, are now available for research. Existing tools for the exploration of digitized newspapers and radio broadcasts nevertheless remain in a fragmented landscape, where automatic processing and computational approaches are typically restricted to one language and one media type. These limitations severely hamper historical research, which is driven by the discovery of relations between their objects of study through iterative processes characterised by comparing, contrasting and associating sources and information.
Impresso establishes the legal and technical prerequisites to build a corpus of historical newspaper and radio collections from our partners. These are newspaper collections from Switzerland, Austria, Belgium, France, Germany, Luxembourg, the Netherlands and the UK spanning the time period of the 19th and the 20th centuries, and radio broadcasts from Switzerland, Austria, France, Germany, the Netherlands and the UK from the 1930s on. For newspapers this includes the collection of page scans, text in METS/ALTO and other XML formats and accompanying bibliographic metadata. For radio, this includes e.g. speaker typescripts, transcribed speech, audio content, radio programmes and accompanying metadata.
We seek to enhance and interconnect historical media collections using both mono- and multilingual natural language processing (NLP) and image processing components. These components help us consolidate, process, enrich, index, link, and connect historical sources.
Semantic enrichment
Our goal is to enrich the consolidated source collection with structured semantic information. This includes fine-grained Named Entity Recognition and Classification (NERC), reliable entity linking, and the extraction of people’s titles and professions. We also aim to determine who said what through the identification of interviews and quote extraction. Additionally, we plan to semantically qualify content units and detect themes using keyphrase extraction, text classification, and multilingual topic modeling. Image documents will be classified and undergo object detection. These enrichments support faceted search and historical research.
Semantic indexing and linking using multilingual dense vector spaces
To enable meaningful content comparison across languages, we will create a shared multilingual dense vector space for semantic indexing. This space will include representations for words, keyphrases, named entities, paragraphs, documents, and images. We will align embeddings between languages, enabling the retrieval of semantically similar content across languages. Hierarchical clustering will group related items, forming the basis for comparative timeline-based views. We will also interlink our content with external knowledge resources, such as Wikipedia, facilitating further search and discovery.
Evaluating the quality of source, enrichment and linking is key. This involves assessing the confidence scores associated with semantic annotations, enabling historians to gauge data quality transparently. The project will undergo both traditional summative evaluation by comparing system outputs with manually created ground truths and formative evaluation during development in collaboration with historians. Two international evaluation campaigns will be organised to foster research in historical document processing.
Overall, our project aims to create a unified and enriched multilingual historical corpus, facilitating advanced research, exploration, and comparison of historical media sources.
See also: Natural Language Processing Objectives
The methodologically reflected analysis of semantically enriched media collections is a challenge in its own right. We therefore focus on the design and implementation of innovative user interfaces to facilitate the exploration, visualisation, and comparison of media collections with the ambition to advance digital (media) history research and methods.
The impresso web app
The Impresso web app we developed during the first Impresso project will be expanded, refined, and scaled up to integrate and adequately represent different types of historical documents (e.g., typescripts or audio alongside newspapers).
The impresso data lab
The newly developed Impresso data lab will offer researchers an API for direct data access, enabling computational analyses beyond the interface’s capabilities. Interactive notebooks make such work more transparent and reusable for research and teaching purposes. Finally, we foresee the ability to link external documents on the grounds of semantic enrichments such as named entities. This with the ambition to allow users to link relevant data to the Impresso corpus whilst also avoiding potential copyright infringement.
In addition to offering a unique gateway to media sources and enrichments, both interfaces will support versatile, transparent and data-driven research workflows that enable methodological reflexivity in the critical analysis of sources, tools and data.
See also: Design Research Objectives
Using enriched and integrated media sources for research in transnational (Media) History
The semantic enrichment of media sources and the design of interfaces are accompanied by historical research case studies which have the overall objective to guide data processing and interface development, stimulate methodological innovation, and produce original research outputs in their own right.
Establishing methods for the methodologically reflected study of our data
Considering the novelty of our corpus and its representation in dense vector spaces, we determine methods for the data-driven study of enriched and connected media sources at scale in light of the principles of digital hermeneutics. This ensures overall relevance of our outputs and evaluates the quality of our data from the perspective of domain experts.
User requirements to guide enrichment and interface development
The project is guided by several historical case studies that produce concrete and diverse user requirements for data and interface design as well as for collaborative research methods. Additional collaborations with external researchers ensure that user requirements and methods are sufficiently broadly defined.
Original research in (Media) History
We conduct original research on historical media ecosystems under the umbrella theme of “influences” to study how newspapers and radio competed and co-evolved. All case studies operate in a shared methodological framework to ensure overall coherence and focus, for example, on Swiss foreign policy, nuclear power and weapons, feminist activists, and the evolution of content formats.
We develop Impresso’s corpus and interfaces with the historical research community at-large in mind. To foster usage of our resources, we are building a community of researchers around our tools and methodological framework. We cooperate with existing research groups in media history and computational humanities and provide opportunities for scholarly exchange and constant feedback.
Overall, historical research explores the opportunities offered by enriched sources using case studies, determines how best to interact with the data, assesses their value for research based on comparative analysis, and fosters a collaborative research community for data-driven and collaborative historical research.
See also: History Research Objectives